How Well Do Vision Models Encode Diagram Attributes?
Jul 24, 2024·
,
,
,
,
,
,
·
0 min read
Haruto Yoshida
Keito Kudo
Yoichi Aoki
Ryota Tanaka
Itsumi Saito
Keisuke Sakaguchi
Kentaro Inui
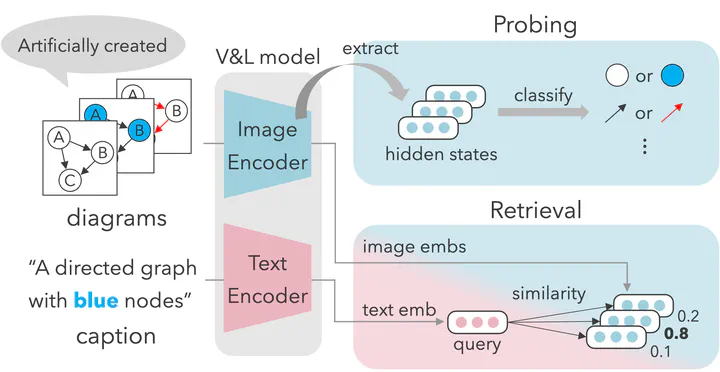 Image credit:
Image credit:
Abstract
Research on understanding and generating diagrams has used vision models such as CLIP. However, it remains unclear whether these models accurately identify diagram attributes, such as node colors and shapes, along with edge colors and connection patterns. This study evaluates how well vision models recognize the diagram attributes by probing the model and retrieving diagrams using text queries. Experimental results showed that while vision models can recognize differences in node colors, shapes, and edge colors, they struggle to identify differences in edge connection patterns that play a pivotal role in the semantics of diagrams. Moreover, we revealed inadequate alignment between diagram attributes and language representations in the embedding space.
Type
Publication
In ACL 2024 Student Research Workshop