ダイアグラム理解に向けた大規模視覚言語モデルの内部表現の分析
Mar 3, 2025·
,
,
,
,
,
,
·
0 min read
吉田 遥音
工藤 慧音
青木 洋一
田中 涼太
斉藤 いつみ
坂口 慶祐
乾 健太郎
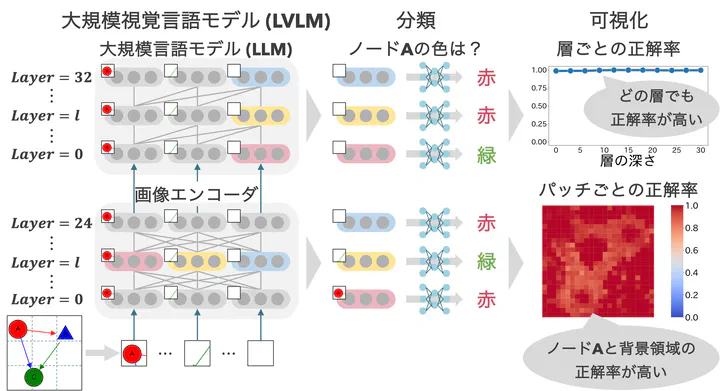 Image credit:
Image credit:
Abstract
ダイアグラムを理解できるAIモデルの実現は,学習支援や情報処理の効率化において重要である.しかし,画像理解タスクで顕著な成果を上げている大規模視覚言語モデル(LVLM)であっても,ダイアグラムのような抽象的かつ構造的な画像の理解には限界がある.本研究では,LVLMがダイアグラムのどのような視覚情報を認識しているか,またそれらの情報をどのように保持しているかを明らかにするため,画像エンコーダおよびLLMの隠れ状態を用いてプロービングを行った.その結果,ノードの色や形,エッジの色や有無の情報はどの層でも10次元程度の低次元の線形部分空間に保持されていたが,エッジの向きの情報は10次元程度の低次元空間には保持されていなかった.また,パッチ単位のプロービングにより,ノードやエッジが描かれていない背景の隠れ状態に,複数のノードやエッジの情報がまとめて保持されていることが示唆された.
Type
Publication
In 言語処理学会第31回年次大会