認知言語学的イメージスキーマの生成と解釈における大規模言語モデルと画像生成モデルの評価
イメージスキーマとは認知言語学において、認知プロセスに繰り返し現れるパターンを表現する図である。しかしこのパターンは人間が同定する必要があるため、全てを網羅的に発見することは困難であった。本研究では英語の動詞を対象に、大規模言語モデル(LLM)と画像生成モデルを用いたイメージスキーマの生成を行った。評価の結果、画像生成モデルでは生成が困難であったが、LLMは\LaTeX (TikZ)のコードとして、人間とLLM双方にとって解釈性の高いイメージスキーマを生成できることが示された。これはLLMを用いたイメージスキーマの網羅的発見の可能性を示唆するものである。
Mar 3, 2025
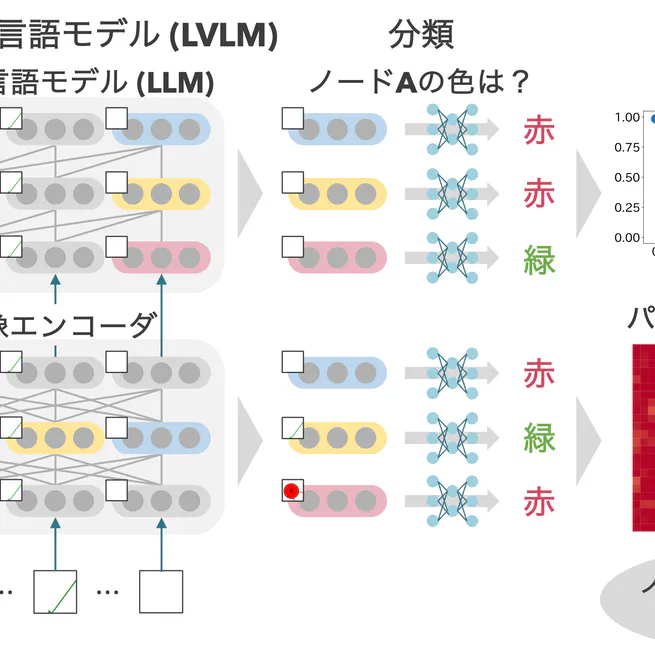
ダイアグラム理解に向けた大規模視覚言語モデルの内部表現の分析
ダイアグラムを理解できるAIモデルの実現は,学習支援や情報処理の効率化において重要である.しかし,画像理解タスクで顕著な成果を上げている大規模視覚言語モデル(LVLM)であっても,ダイアグラムのような抽象的かつ構造的な画像の理解には限界がある.本研究では,LVLMがダイアグラムのどのような視覚情報を認識しているか,またそれらの情報をどのように保持しているかを明らかにするため,画像エンコーダおよびLLMの隠れ状態を用いてプロービングを行った.その結果,ノードの色や形,エッジの色や有無の情報はどの層でも10次元程度の低次元の線形部分空間に保持されていたが,エッジの向きの情報は10次元程度の低次元空間には保持されていなかった.また,パッチ単位のプロービングにより,ノードやエッジが描かれていない背景の隠れ状態に,複数のノードやエッジの情報がまとめて保持されていることが示唆された.
Mar 3, 2025
Sketch2Diagram: 視覚的指示を入力とするダイアグラム生成
スケッチ画像を理解してベクター形式のダイアグラムを生成するためのベンチマークデータセットSkeTikZを提案する.SkeTikZは,人手で作成したスケッチ画像とTikZ形式のダイアグラムがペアになった初めてのデータセットである.さらに,画像を理解してベクター形式のダイアグラムを生成可能なマルチモーダルモデルImgTikZを提案する.ImgTikZは,コード生成に特化した大規模言語モデルと画像エンコーダを活用したモデルであり,実験によって7B規模のモデルサイズながらGPT-4oに匹敵するダイアグラム生成能力を有することを確認した.また,スケッチ作成のツールによって画像認識の難易度が大きく変わることを確認した.
Mar 3, 2025
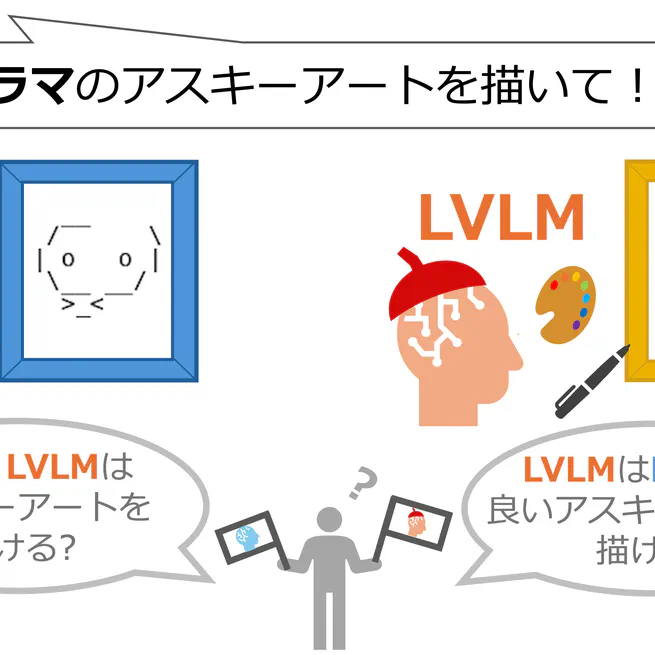
ASCII Challenge ---LLMは画家になれるか---
アスキーアートはイラストや画像を文字で表現するテキストアートである.文字だけを用いて様々な表現を可能にするアスキーアートは現代社会で広く用いられている一方で,その作成は容易ではない.また既存の生成ツールは画像を機械的に変換するなど柔軟性が低い方法に限定されている.本研究では,自然言語からアスキーアートを生成する手段としてのLLM・LVLMの利用可能性の検証を行った.結果として現行のモデルでは生成が困難だが,アスキーアートに特化したデータセットを用いて学習することで生成可能になる兆しが見えた.
Mar 3, 2025
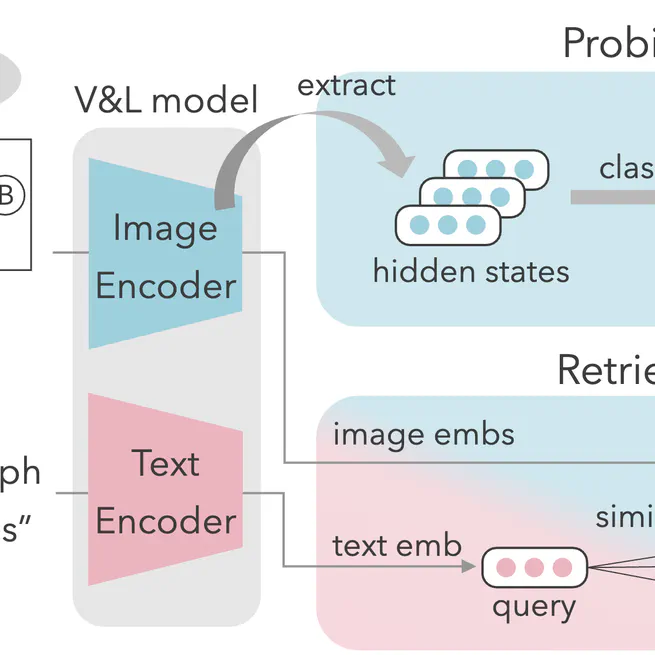
How Well Do Vision Models Encode Diagram Attributes?
Research on understanding and generating diagrams has used vision models such as CLIP. However, it remains unclear whether these models accurately identify diagram attributes, such as node colors and shapes, along with edge colors and connection patterns. This study evaluates how well vision models recognize the diagram attributes by probing the model and retrieving diagrams using text queries. Experimental results showed that while vision models can recognize differences in node colors, shapes, and edge colors, they struggle to identify differences in edge connection patterns that play a pivotal role in the semantics of diagrams. Moreover, we revealed inadequate alignment between diagram attributes and language representations in the embedding space.
Jul 24, 2024
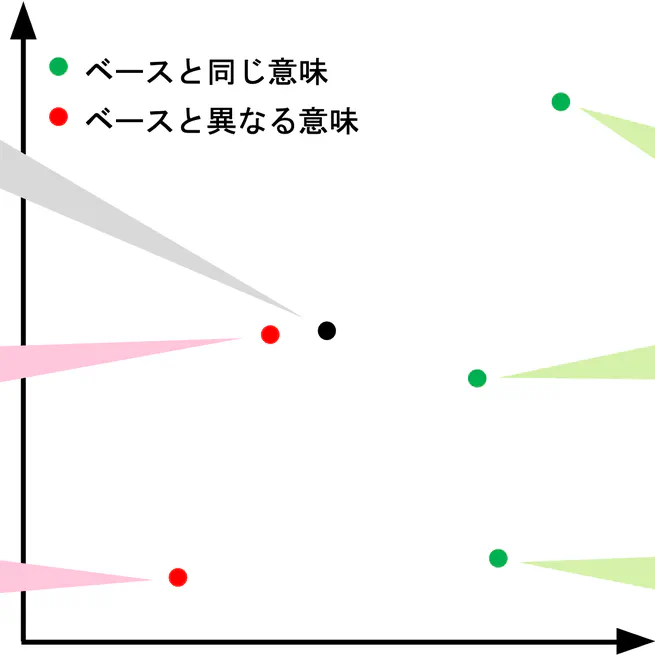
自然画像で学習された画像埋め込みにダイアグラムを特徴づける情報は含まれているか?
ダイアグラムの意味やデザインを考慮して分類や検索,評価を行うための道具として,画像埋め込みがある.しかし,既存の事前学習済み画像モデルから得られる埋め込みに,ダイアグラムを特徴づける情報が十分に含まれているかは明らかでない.本研究では,エッジの向きやノードの形といった要素が異なるダイアグラムの埋め込み分布を比較し,事前学習済みモデルから得られる画像埋め込みがダイアグラムを特徴づける情報を含んでいるかを調べた.既存の事前学習済みモデルから得られる埋め込みはダイアグラムを特徴づける情報を十分には含んでいない可能性があり,ダイアグラムを扱うことができるモデルの必要性が示唆された.
Feb 11, 2024